
Zitat von
Solwac
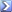
Wie man sieht (mit sieben Linien ist die Grafik ausgereizt, mehr würde nur schwer erkennbar sein), so zappeln die Ratings kräftig herum. Nur noch etwa 35% liegen im Intervall mit den Unsicherheiten eines Turniers mit 250 Runden.
Diese Simulation bewegt sich jetzt ungefähr in der Größenordnung der SSDF-Liste vor 25 Jahren. Die Auswertung für Menschen mit ihrer zeitlichen Abhängigkeit ist also ungeeignet um Computerpartien auszuwerten.
Klar, an der Grafik sieht man deutlich dass hier natürlich bei der FIDE-Auswertung gewisse Ungenauigkeiten da sind. Es schwänzeln zwar alle immer um die richtige ELO-Zahl rum, jedoch sind teilweise schon große Ausreisser zu sehen. Früher wurden die FIDE-Listen ja halbjährlcih erstellt, dann im 3-Monats-Intervall, heute monatlich. In dem 3 Monatsintervall (der übrigend beim Fernschach auch vom ICCF verwendet wird) dürften die Schwankungen nicht ganz so groß sein, als wenn man wirklich jedes einzelne Turnier für sich auswertet., In so einem Fall käme man möglicherweise zu einem brauchbaren Ergebnis, welches aber nur für eine gemischte Liste (Mensch/Maschine) überhaupt einen Sinn ergibt. Für eine reine Computerliste ist unter der Voraussetzung dass wir bisher noch keine selbstlernenden Programme auf breiter Basis haben die Bayes Methode tatsächlich die genaueste Möglichkeit. Wie schon gesagt, es kommt halt drauf an, was man erreichen oder aussagen will und auch dass die Rahmenbedingungen für eine Auswertung stimmen. Und dazu hast Du ja alles geschrieben. Ich denke hier im Forum sind wir auf dem richtigen Weg. Ein paar genauere Worte zur Erklärung wie die Zahlen entstanden sind und dann sollens die Leute eben so hinnehmen oder lassen. Andere Listen gibts nicht.
Zitieren:
Wollte man Computer richtig auswerten, dann müsste man in einem weiten Bereich Partien gegen Menschen spielen, dies funktioniert aber wohl nur bis etwa zwischen 1600 und 2400 Elo
Mangels stärkerer Spieler die gegen Computer spielen gebe ich Dir da recht. Aber das wäre dann halt die Auswertung der Maschine im Vergleich zum Menschen und damit natürlich realitätsnah, während man bei den reinen Computerlisten eben diesen Vergleich nicht hat. Kommt halt immer drauf an, was man zeigen will.
Zitieren:
Was bleibt also? Sauber zu arbeiten, so wie z.B. hier im Forum oder bei der SSDF, gut nachvollziehbar zu beschreiben wie die Ratingliste zustande kommt und Hinweise zur Übertragbarkeit der Werte auf Partien gegen Menschen zu geben. Wenn ich mir die Listen hier im Forum so anschaue, dann fehlen vielleicht noch ein, zwei Sätze in der Beschreibung und das war's. Und natürlich der Hinweis an die, die es nicht glauben können oder wollen, es besser zu machen. Wenn die das dann aber probieren, dann will ich eine Tüte Popcorn.

Besser kann man es nicht sagen. Nur das ist das Problem der großen Listen. Das mit der sauberen Arbeit. Wenn ich schon immer die Hinweise sehe (so musst Du umrechnen wenn Du statt des Referenzrechners einen mit diesem Prozessor und jener Geschwindigkeit hast) dann schüttel ich eigentlich nur noch den Kopf und sage mir: "Schade um die ganze Arbeitszeit der Tester... geht lieber in den Biergarten"
Bei uns ist nahezu alles nachvollziehbar und das ist gut so. Ich sehe nicht warum Micha irgendwas ändern sollte.